与传统的冯诺依曼计算相比,神经形态计算提供了一种提高能效的替代方法。与有监督和无监督学习不同,强化学习(RL)是机器学习范式之一,它允许机器与环境交互并根据负或正奖励信号更新策略。RL的算法主要包括基于人工神经网络(ANN)的深度Q学习(DQN)和基于脉冲神经网络(SNN)的奖励调制的尖峰时序依赖可塑性(R-STDP)。与采用误差反向传播和梯度下降来更新权重的ANN基DQN相比,R-STDP通过将类脑STDP与奖励信号相结合来更新权重在生物学上更合理。R-STDP学习规则主要依靠来自外部环境的奖励项(正或负奖励)对“标准”STDP的调制,从而实现SNN基强化学习。R-STDP存储符合STDP条件的突触轨迹,并在接收到正/负奖励信号时施加调制的权重变化。具有原子级厚度的2D半导体场效应晶体管(FET)显示出出色的静电可调性,这为STDP和反STDP学习规则提供了将沟道调制为可重构p型或n型的可能性。
有鉴于此,华中科技大学ISMD团队联合香港理工大学展示了一种以并行结构连接的两个突触晶体管(2T)设计。由于非易失性铁电极化,基于WSe2铁电晶体管的2T单元表现出可重构的极性行为,其中一个沟道可以调谐为n型,而另一个沟道可以调谐为p型。通过这种方式,本文实现了具有多级(>6位)电导状态、超低非线性(0.56/-1.23)和大Gmax/Gmin比(30)的相反突触权重更新行为。通过对2T单元的(反)STDP组分施加正/负奖励,本文实现了R-STDP学习规则,用于训练脉冲神经网络,并演示了解决经典的推车-杆问题,展示出一种实现用于强化学习的低功耗(每个正向过程32 pJ)和高面积效率(100μm2)硬件芯片方法。文章以“Reconfigurable two-WSe2-transistor synaptic cell for reinforcement learning”为题发表在顶级期刊Advanced Materials上,论文的第一作者为ISMD的博士生周越同学,通讯作者为华中科技大学何毓辉教授,缪向水教授和香港理工大学柴扬教授。
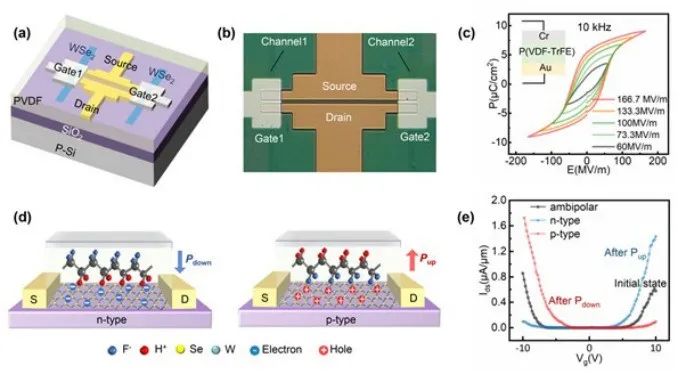
本文展示了一个具有两个极性可调WSe2晶体管的突触单元。通过非易失性铁电极化在两个沟道中预先安排相反的载流子类型,该单元能够以100 μm2的芯片尺寸紧凑地实现R-STDP。通过进一步将2T单元实现的R-STDP用于SNN训练,本文证明了在推车-杆问题中每个推理过程的功耗低至32pJ。这项工作为RL基SNN硬件芯片与2T单元基突触的应用开辟了一条途径。
文章信息:
Reconfigurable two-WSe2-transistor synaptic cell for reinforcement learning (Adv. Mater., 2022, DOI:10.1002/adma.202107754)
文章链接:
https://onlinelibrary.wiley.com/doi/10.1002/adma.202107754