6月21日,集成电路学院李祎副教授、缪向水教授研究团队在高能效忆阻科学计算方面的最新成果以“Sparse matrix multiplication in a record-low power self-rectifying memristor array for scientific computing” 为题在线发表在《科学进展》(Science Advances)。该研究基于超低功耗自整流忆阻器阵列,首次提出利用器件非线性实现高面积效率、高计算并行度的稀疏矩阵运算以加速科学计算应用。
科学计算是基础科学研究和工业制造的重要技术,高性能计算机的性能提升是科学计算进一步发展的关键硬件基础。基于忆阻器的存算一体技术及硬件已在加速神经网络中的稠密矩阵计算方面取得了显著进展。然而,在加速科学计算中常见的大规模稀疏矩阵计算时,由于阵列集成规模和模拟计算原理等方面的限制,硬件开销巨大,无法充分发挥忆阻存算一体的能效优势。为解决上述问题,团队通过新忆阻器件、新计算原理、存算一体新电路及新架构的跨层面协同研究,以突破稀疏矩阵计算的能效限制,推动忆阻存算一体技术在高性能计算场景下的应用。
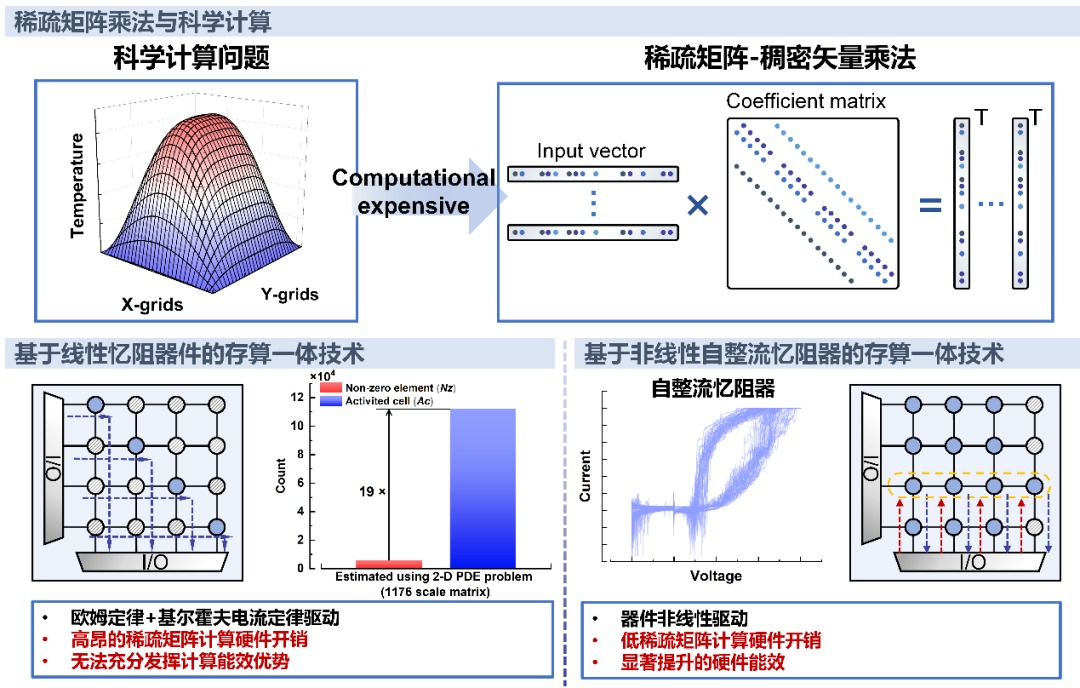
图1.基于自整流忆阻器的存算一体为稀疏矩阵计算提供了一种高能效计算方法
在此背景下,该研究实现了以下几个方面的技术突破:(1)在器件层面,制备了高性能的Pt/HfO2/TaOx/Ta自整流忆阻器阵列,其具有极低的漏电流(小于0.1 pA),而且功耗优于国际上已有文献报道值(SET: 2.4 aJ,RESET: 150 aJ;读取功耗LRS: 150 aJ,HRS: 0.12 aJ),为实现高能效大规模计算奠定了重要基础。(2)在模拟计算机制方面,首次提出了一种基于器件非线性的模拟存算一体机制,并在阵列中实现了稀疏矩阵压缩与高并行计算,显著降低了硬件开销和电路功耗。(3)最后,通过电路、算法和混合精度计算架构的跨层次协同优化,成功在实际科学计算任务上取得了与双精度浮点计算系统相媲美计算精度,并将2-bit至8-bit的稀疏矩阵计算能提高到了97 – 11 TOPS/W。相较于现有的存算一体技术,本系统的面积效率提升了340倍,能效提升超过85倍。这项工作克服了忆阻存算一体技术在科学计算应用上的关键性能瓶颈,为推动忆阻存算一体技术在高性能计算领域的发展迈出了坚实一步。
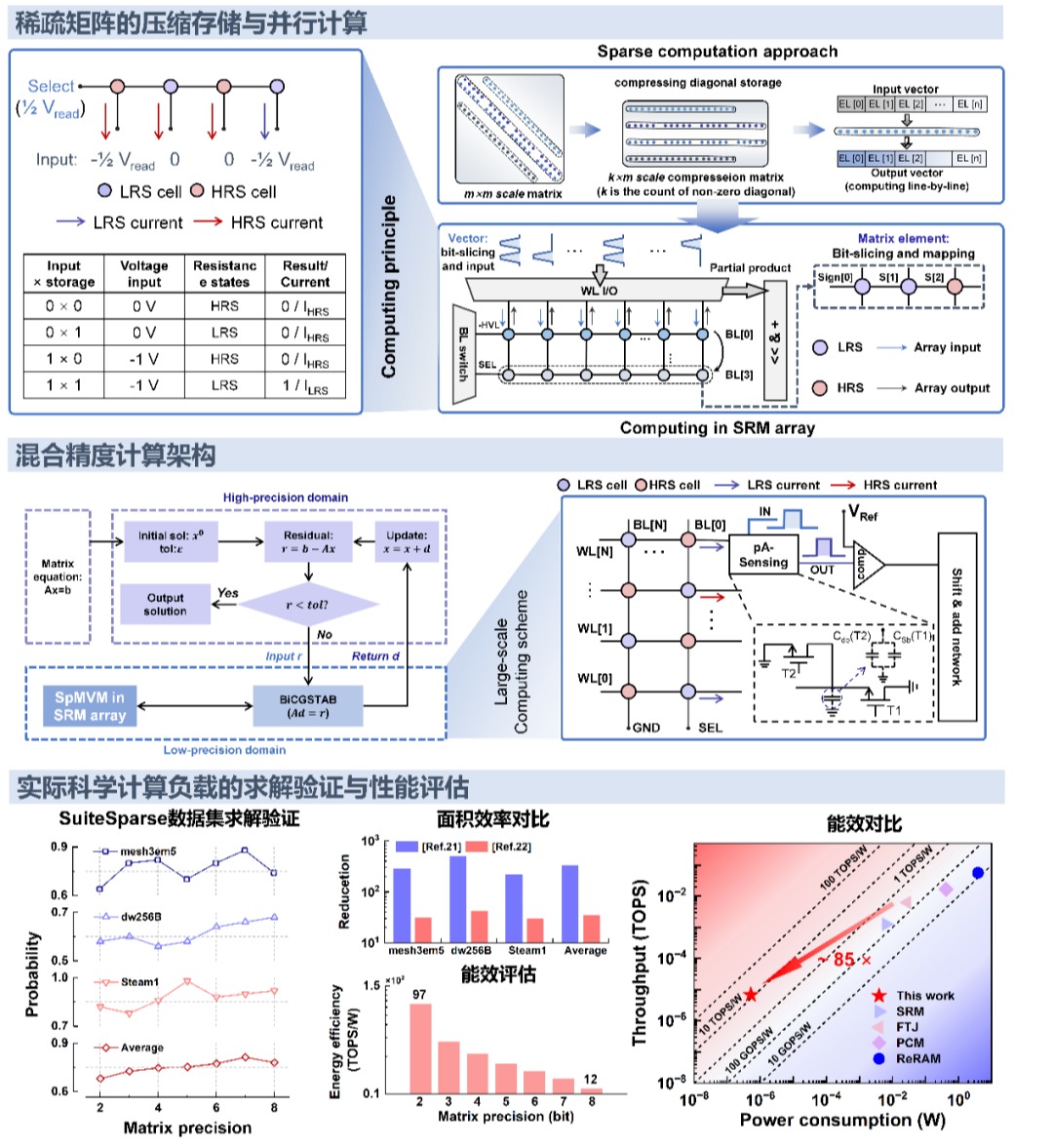
图2.基于自整流忆阻器的稀疏矩阵计算在科学计算上的应用验证及与现有存算一体技术的性能对比
该研究工作得到了科技部国家重点研究计划、国家自然科学基金“后摩尔时代新器件基础研究”重大研究计划培育项目的资助,以及湖北江城实验室的支持。华中科技大学为论文第一完成单位,集成电路学院博士研究生李健聪和任升广为共同第一作者,李祎副教授和缪向水教授为论文共同通讯作者。
https://www.science.org/doi/10.1126/sciadv.adf7474